
Это команда Insight Custdev, и мы сделали AI-ассистента, который проводит кастдевы в переписке в масштабе до 6000 человек в день.
Хотим в формате кейса рассказать, как мы реализовали один из наших последних проектов и улучшили нашу методологию и продукт.
Запрос на исследование
Однажды к нам пришел заказчик, это была онлайн-школа «Мама Знайка», они обучают педагогов и родителей тому, как лучше обучать детей. Запрос: “нужны идеи продуктов для уже состоявшейся базы, идеи для улучшения маркетинговой коммуникации”.
Они хотели актуализировать знания о своей аудитории, и лучше понять аудиторию: да, были результаты прошлых исследований, но казалось, что они устарели.
Имея большую, формировавшуюся годами базу, они как нельзя лучше подходили под исследование через AI-ассистента-кастдевера. Исследование происходит на стыке качественных и количественных, на выходе мы получаем как качественные данные (инсайты о болях, проблемах, стремлениях и прочем), так и количественные (процентную разбивку по этим данным, условно “боль 1” у 43% аудитории, а “боль 2” - всего у 14%. Это значит что “боль 1” преобладает и более триггерная для аудитории.
Итак, вперед, что из этого вышло.
Определяем цели исследования и готовим вопросы
Самое первое: мы должны были погрузиться в продукты. Прошлись по всем лендам/сайтам, пробежали все маркетинговые воронки, подняли все старые исследования, прочекали всю коммуникацию с аудиторией, углубились в текущую сегментацию.
Забрифовали клиента, расставили цели, декомпозировали их на задачи и приступили к работе.
Далее: сформировали скрипт из 21 вопроса и согласовали с командой
Так как мы провели уже миллион (возможно чуть меньше, не намного) глубинок, мы полностью понимаем, как составлять гайды под интервью.
Да, интервью в переписке это не то же самое, тут есть ряд особенностей. Например внимание пользователя к чату сохраняется около 15 минут, и чем дольше диалог, тем меньше людей доходит до конца.
Но мы к этому готовы и знаем эти нюансы, знаем как делать как надо (как не надо - тоже знаем).
Забрифовали клиента, расставили цели, декомпозировали их на задачи и приступили к работе.
Далее: сформировали скрипт из 21 вопроса и согласовали с командой
Так как мы провели уже миллион (возможно чуть меньше, не намного) глубинок, мы полностью понимаем, как составлять гайды под интервью.
Да, интервью в переписке это не то же самое, тут есть ряд особенностей. Например внимание пользователя к чату сохраняется около 15 минут, и чем дольше диалог, тем меньше людей доходит до конца.
Но мы к этому готовы и знаем эти нюансы, знаем как делать как надо (как не надо - тоже знаем).
Настройка бота, приглашение на опрос и его проведение
К текущему моменту у нас уже была выстроена платформа, наша собственная разработка, на базе которой работал наш бот. Мы запускали его в Телеграме, все проекты были реализованы на ChatGPT, выбирали самые актуальные версии на момент исследования.
Мы загрузили наш скрипт в бота, который как раз укладывался в 15-16 минут разговора.
Были также сформированы 18 принципов общения бота с человеком: для нас было важно, чтобы AI-кастдевер углублялся в суть вопроса, копал в глубину, уточнял, если пользователь отвечал односложно, возвращал к вопросам, проявлял эмпатию, был вежлиым и мотивирующим к ответам.
Для привлечения пользователей в бота мы использовали емейл, рассылки по базе в ВК и ТГ. Составили для них письма, но финальную редактуру оставили на стороне заказчика. Пользователей привлекали через лид-магнит.
Один из этапов работы - тестовая рассылка на небольшую часть аудитории, она нужна для того, чтобы убедиться в правильности вопросов, все ли необходимые данные мы получаем из интервью, все ли нам хватает, а также как ведут себя подписчики. После тестов, если необходимо, дорабатываем скрипт и исправляем ошибки.
Финально у нас уходило по три письма на каждый канал, в которых призывали пообщаться с ботом. Переписка шла отлично, никаких ошибок или сбоев. Все шло хорошо, завершаемость была отличная, все были довольны =)
Мы загрузили наш скрипт в бота, который как раз укладывался в 15-16 минут разговора.
Были также сформированы 18 принципов общения бота с человеком: для нас было важно, чтобы AI-кастдевер углублялся в суть вопроса, копал в глубину, уточнял, если пользователь отвечал односложно, возвращал к вопросам, проявлял эмпатию, был вежлиым и мотивирующим к ответам.
Для привлечения пользователей в бота мы использовали емейл, рассылки по базе в ВК и ТГ. Составили для них письма, но финальную редактуру оставили на стороне заказчика. Пользователей привлекали через лид-магнит.
Один из этапов работы - тестовая рассылка на небольшую часть аудитории, она нужна для того, чтобы убедиться в правильности вопросов, все ли необходимые данные мы получаем из интервью, все ли нам хватает, а также как ведут себя подписчики. После тестов, если необходимо, дорабатываем скрипт и исправляем ошибки.
Финально у нас уходило по три письма на каждый канал, в которых призывали пообщаться с ботом. Переписка шла отлично, никаких ошибок или сбоев. Все шло хорошо, завершаемость была отличная, все были довольны =)
Анализ (приключение на 10 минут, зайти и выйти)

А вот тут уже началось.
Объем данных получился гораздо большим, чем мы ожидали. 28000 строк сырых данных – это все диалоги наших респондентов с AI-исследователем, причем каждая строка - это вопрос от бота и ответ от респондента. И это все предстояло проанализировать.
С таким объемом человек не справится.
Не справилась и наша методология, которую мы использовали на других проектах до этого.
Почему? Потому что она ломалась на таких больших объемах.
Перед нами встал вопрос: а что делать?
Мы попробовали запихнуть всю сырую таблицу в несколько нейронок, с которыми работали, но все они отказались анализировать. ChatGPT, например, из всей базы брал только 30 человек, анализировал их, а всех остальных пользователей считал несуществующими. Gemini делал также, но остальных не просто вычеркивал, а придумывал заново (галлюцинации). Другие поступали примерно также.
Вывод: контекстное окно не дает гарантии того, что нейронка сможет отработать корректно.
Вывод для нашей команды: все фигня, надо переделывать
Объем данных получился гораздо большим, чем мы ожидали. 28000 строк сырых данных – это все диалоги наших респондентов с AI-исследователем, причем каждая строка - это вопрос от бота и ответ от респондента. И это все предстояло проанализировать.
С таким объемом человек не справится.
Не справилась и наша методология, которую мы использовали на других проектах до этого.
Почему? Потому что она ломалась на таких больших объемах.
Перед нами встал вопрос: а что делать?
Мы попробовали запихнуть всю сырую таблицу в несколько нейронок, с которыми работали, но все они отказались анализировать. ChatGPT, например, из всей базы брал только 30 человек, анализировал их, а всех остальных пользователей считал несуществующими. Gemini делал также, но остальных не просто вычеркивал, а придумывал заново (галлюцинации). Другие поступали примерно также.
Вывод: контекстное окно не дает гарантии того, что нейронка сможет отработать корректно.
Вывод для нашей команды: все фигня, надо переделывать

Анализ, очередные попытки
Далее мы попробовали упростить для нейронки задачу, и придумали отдавать ей сразу аватары пользователей. Мы разбили базу на пачки по 30 человек и просили у ИИшки составить портрет каждого пользователя по определенной структуре.
Получилось муторно, долго, но правдиво: у каждого пользователя был свой портрет, с которым можно было работать.
Для чего все это: у нас была гипотеза, что с портретами нейронка справится лучше, чем с отдельными строками в таблице.
Но она себя не подтвердила: по итогу мы сделали много лишних телодвижений, потратили еще одну неделю и кучу сил, но так и не смогли заставить нейронки отдать нам внятный и корректный анализ, все результаты были либо поверхностными, либо галлюцинациями, и не проходили проверок.
Мы опять вернулись к “Все фигня, переделывай”
Все следующие гипотезы давали нам такие поверхностные, невнятные результаты, которыми мы были недовольны. Казалось, что в процессе анализа мы потеряли глубину, потеряли что-то важное, потеряли глубинные смыслы и сущностный контекст - то, ради чего и делают такие исследования.
В целом, даже такой результат можно было назвать результатом. Там также были инсайты, также была информация об аудитории, он был расписан по всем болям/потребностям/стоп-факторам, но суть была пустой. Мы очень устали от проекта, хотелось сдать его поскорее, мы реально упоролись. Хотелось отдать такой результат, но мы не стали.
Накануне отчетной встречи с презентацией результатов мы честно признались заказчику, что результат – ерунда, мы им недовольны, и не можем отдавать такое.
И начали анализ заново...
Получилось муторно, долго, но правдиво: у каждого пользователя был свой портрет, с которым можно было работать.
Для чего все это: у нас была гипотеза, что с портретами нейронка справится лучше, чем с отдельными строками в таблице.
Но она себя не подтвердила: по итогу мы сделали много лишних телодвижений, потратили еще одну неделю и кучу сил, но так и не смогли заставить нейронки отдать нам внятный и корректный анализ, все результаты были либо поверхностными, либо галлюцинациями, и не проходили проверок.
Мы опять вернулись к “Все фигня, переделывай”
Все следующие гипотезы давали нам такие поверхностные, невнятные результаты, которыми мы были недовольны. Казалось, что в процессе анализа мы потеряли глубину, потеряли что-то важное, потеряли глубинные смыслы и сущностный контекст - то, ради чего и делают такие исследования.
В целом, даже такой результат можно было назвать результатом. Там также были инсайты, также была информация об аудитории, он был расписан по всем болям/потребностям/стоп-факторам, но суть была пустой. Мы очень устали от проекта, хотелось сдать его поскорее, мы реально упоролись. Хотелось отдать такой результат, но мы не стали.
Накануне отчетной встречи с презентацией результатов мы честно признались заказчику, что результат – ерунда, мы им недовольны, и не можем отдавать такое.
И начали анализ заново...

Поняли как анализировать, но не сразу
Признав собственную некомпетентность в работе с большими объемами неструктурированных данных, мы поняли, что мы в тупике. Пришлось дать себе отчет в том, что мы чего-то не знаем.
Наступило время роста. И мы пошли ресерчить рынок и брать консультации.
После серии встреч с лидерами в направлении анализа, обработки данных, работы с нейросетями, мы начали нащупывать верную дорогу.
Решение, к которому пришли - работать прямо в гугл-таблице, превратив ее в нашу базу данных, а также подключить через скрипты по API все наши любимые нейронки, каждую из которых превратили в агента еще до того, как это стало мейнстримом.
Итак, по шагам!
Наступило время роста. И мы пошли ресерчить рынок и брать консультации.
После серии встреч с лидерами в направлении анализа, обработки данных, работы с нейросетями, мы начали нащупывать верную дорогу.
Решение, к которому пришли - работать прямо в гугл-таблице, превратив ее в нашу базу данных, а также подключить через скрипты по API все наши любимые нейронки, каждую из которых превратили в агента еще до того, как это стало мейнстримом.
Итак, по шагам!
Финальный анализ
Изначально имелось 28к строк, где каждая строка - это вопрос и ответ пользователя.
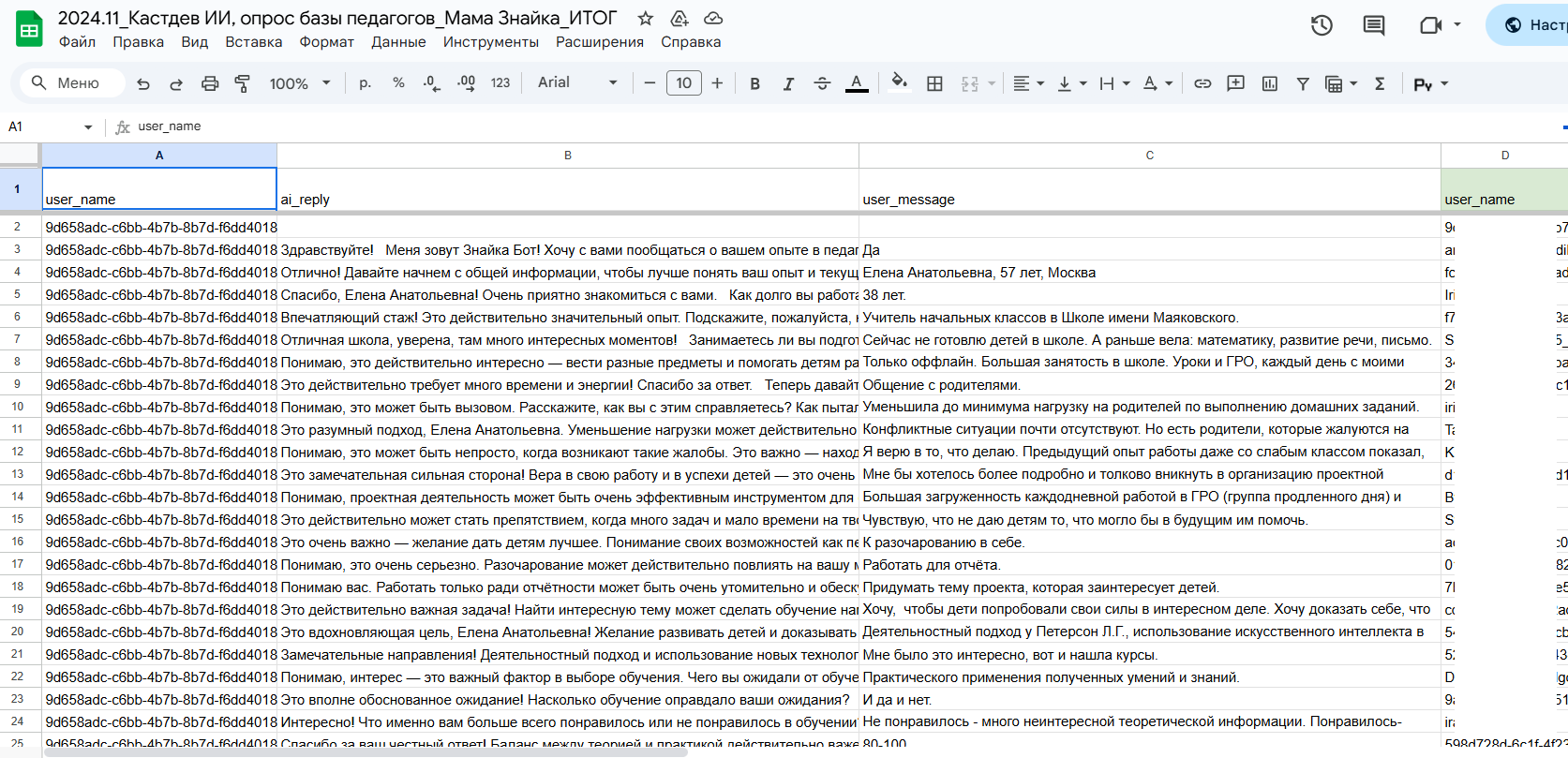
Мы собрали каждый диалог пользователя в одной ячейке, таким образом сократили количество строк до 696, т.е. получили 696 диалогов пользователей.
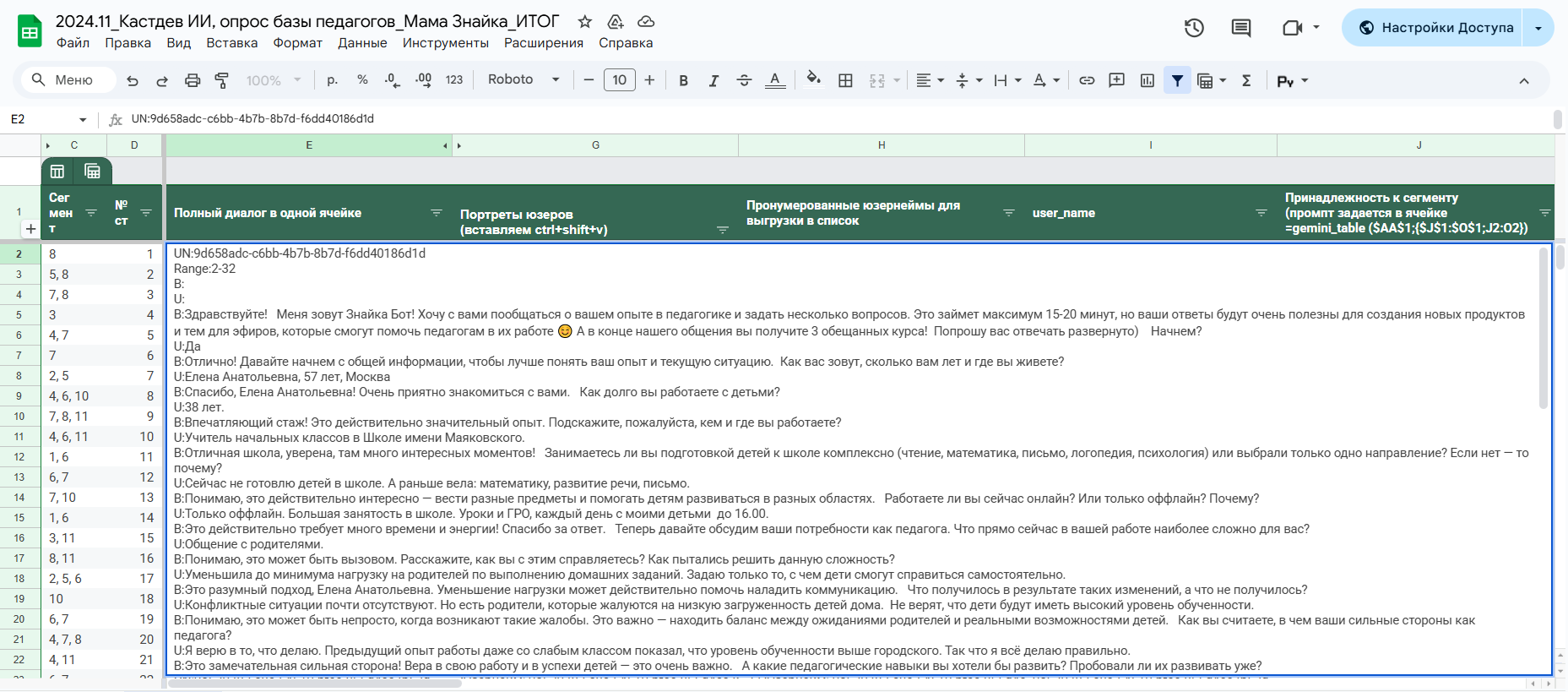
Через несколько итераций мы собрали AI-агента прямо внутри нашей таблицы, который выдавал итоговый портрет по каждому пользователю со всеми характеристиками: боли, потребности, стоп-факторы и другое. Причем добились того, чтобы он интерпретировал ответы в сочетании с вопросами, а не пытался составить общую характеристику на основе только сказанного пользователем. Поверьте, это очень важно, в данном случае контекст решает многое.
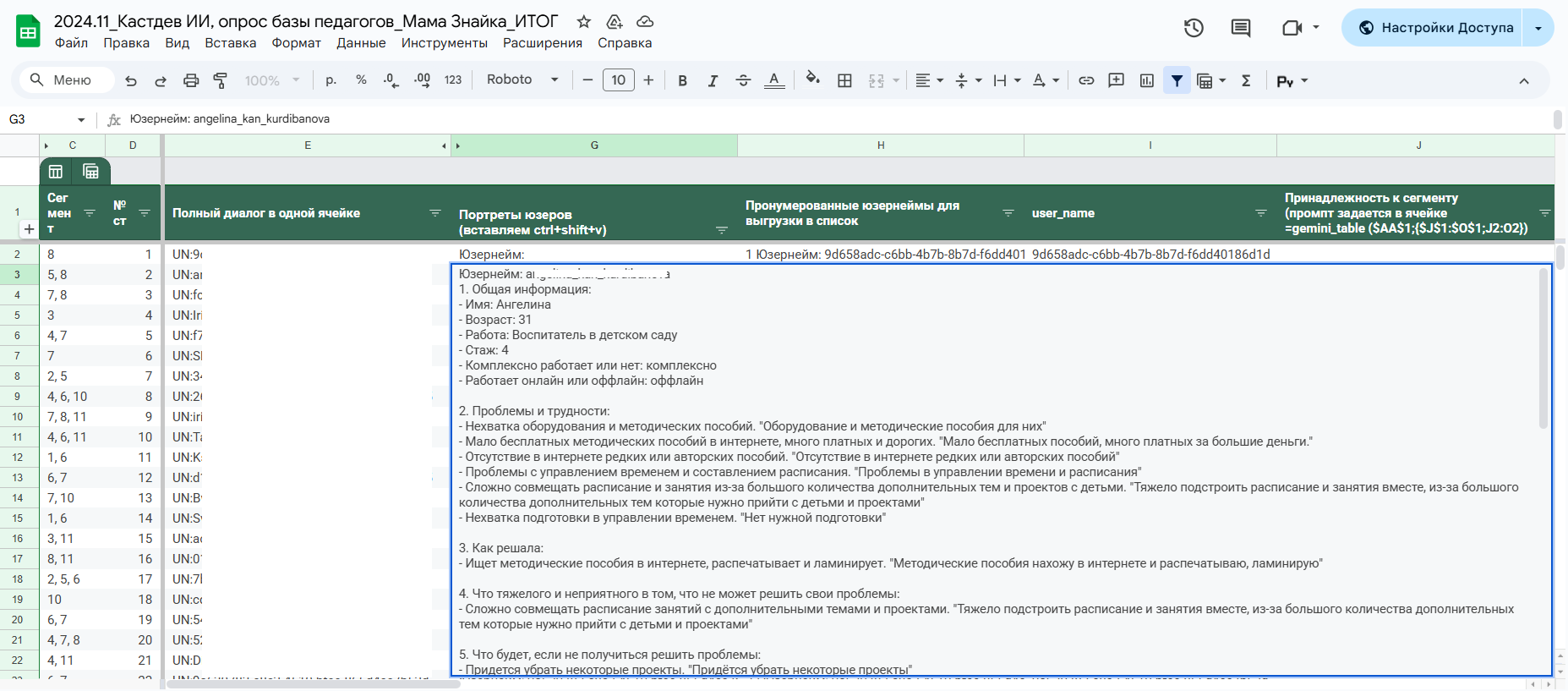
В прошлый раз мы сгружали портреты пользователей для анализа целиком, но в этот раз мы решили разбить каждую характеристику по каждому пользователю в отдельную ячейку в таблице.
Это для того, чтобы можно было отдельно анализировать нужные нам характеристики, включать или исключать их из анализа, не перегружая контекстное окно нейронки. Это исключало галлюцинации и дало нужную глубину данных.
Если ничего не понятно, то вот скриншот, хотя и там не особо понятно =)
Это для того, чтобы можно было отдельно анализировать нужные нам характеристики, включать или исключать их из анализа, не перегружая контекстное окно нейронки. Это исключало галлюцинации и дало нужную глубину данных.
Если ничего не понятно, то вот скриншот, хотя и там не особо понятно =)
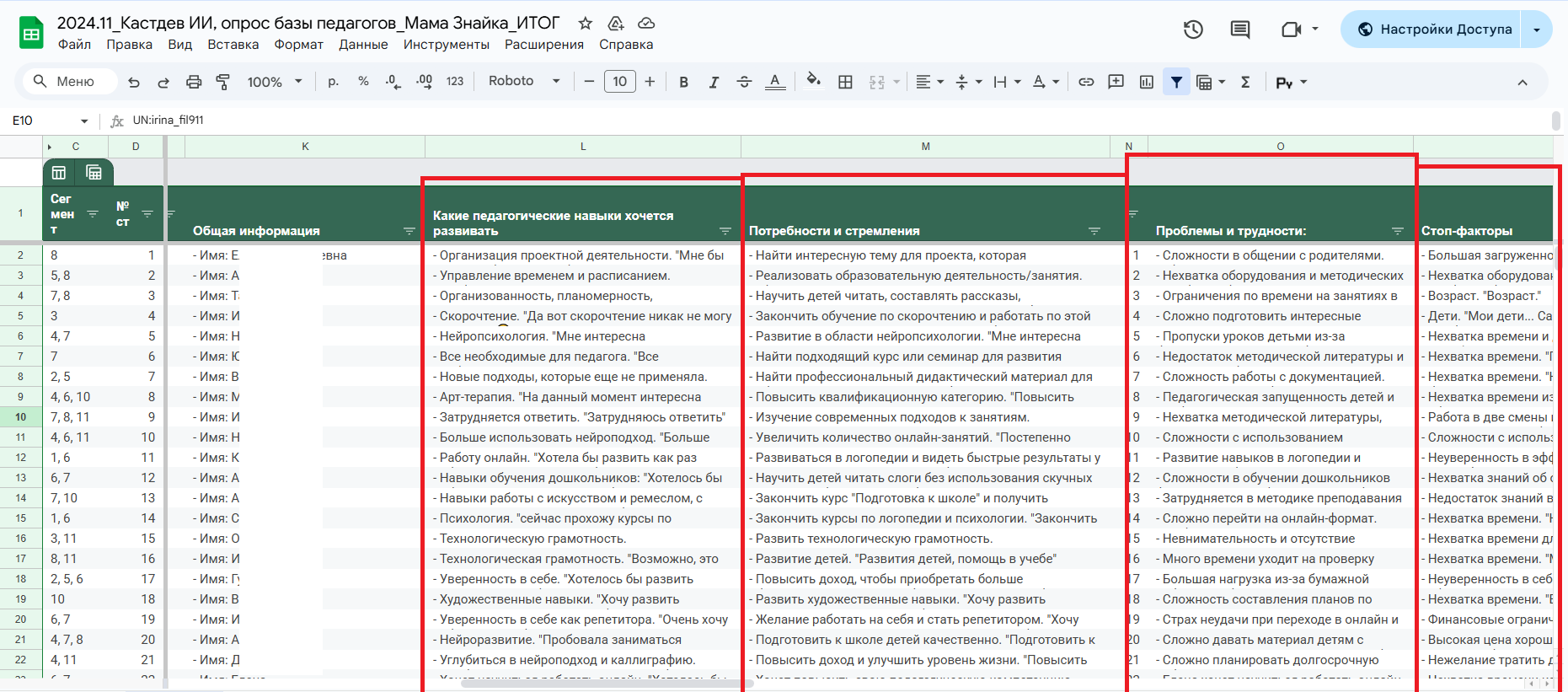
Далее мы определились с сегментами. Разбивали по ключевому результату, к которому хочет прийти человек. Получили 9 основных сегментов.
Теперь по каждому полученному сегменту мы анализировали каждую из характеристик: отдельно проблемы сегмента 1, отдельно потребности сегмента 1, отдельно методы решения проблемы сегмента 1 и так далее.
По итогу вышел анализ каждого сегмента с подтверждающими цитатами.
Также мы выводили процентное соотношение по каждому тезису: какая боль встречается чаще, какая - реже, и так далее. Поэтому мы сразу знаем, что отзывается у аудитории, что для нее значимо, а что – нет.
Более подробно на скрине
Теперь по каждому полученному сегменту мы анализировали каждую из характеристик: отдельно проблемы сегмента 1, отдельно потребности сегмента 1, отдельно методы решения проблемы сегмента 1 и так далее.
По итогу вышел анализ каждого сегмента с подтверждающими цитатами.
Также мы выводили процентное соотношение по каждому тезису: какая боль встречается чаще, какая - реже, и так далее. Поэтому мы сразу знаем, что отзывается у аудитории, что для нее значимо, а что – нет.
Более подробно на скрине
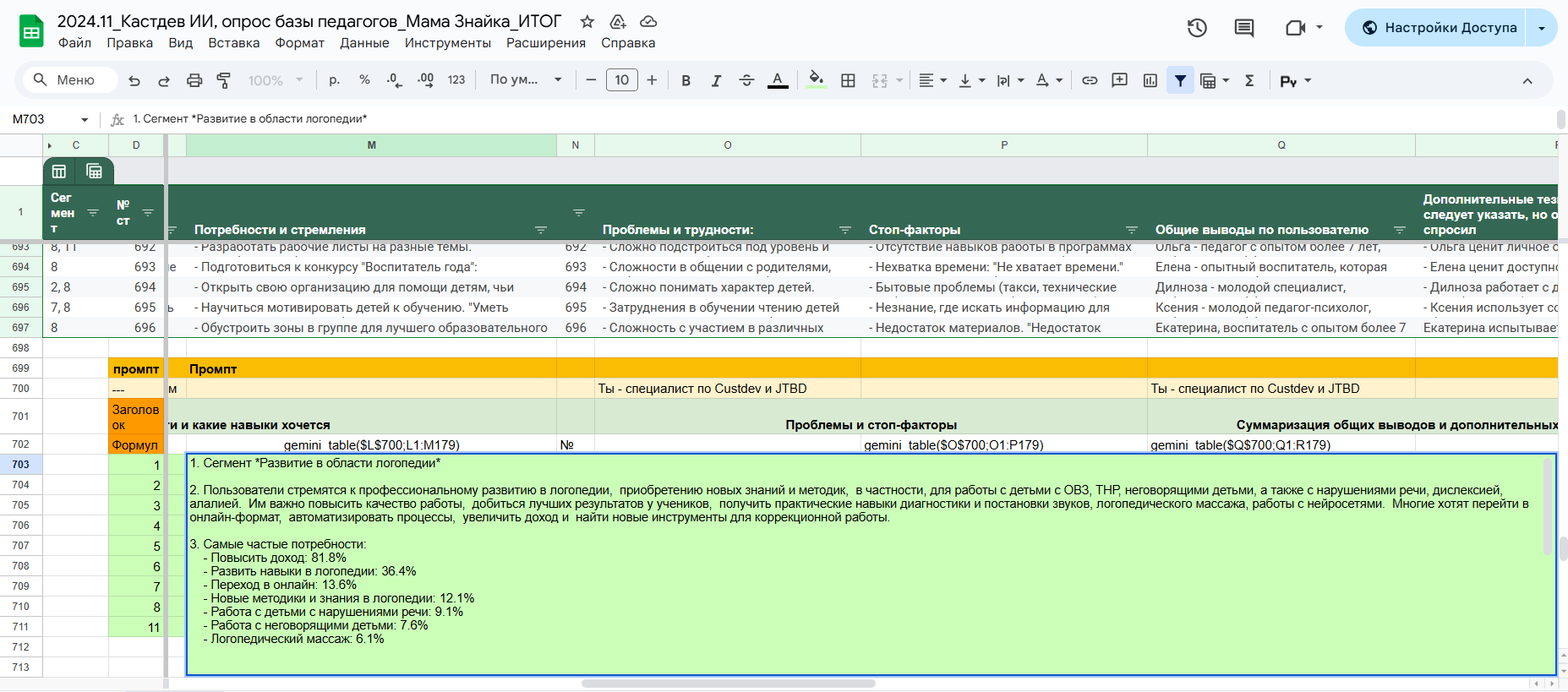
Теперь мы имеем полный анализ имеющейся базы школы «Мама Знайка», с описанием всех сегментов.
А дальше мы сформировали продуктовые гипотезы, в том числе и идеи новых продуктов, прописали идеи по контенту, по лид-магнитам, по воронкам.
Ну и передали все команде «Мама Знайка», конечно же.
А дальше мы сформировали продуктовые гипотезы, в том числе и идеи новых продуктов, прописали идеи по контенту, по лид-магнитам, по воронкам.
Ну и передали все команде «Мама Знайка», конечно же.
Что в итоге?
Подготовили отчеты:
Потрачено времени: месяц
Потрачено сил: очень много
Получено: новая методология, бесценный опыт, детально изученная база клиента.
Таким образом мы прошли путь от наивной, но надежной и эффективной команды до поседевшей, но такой же надежной и эффективной команды, улучшили нашу методологию и нашу услугу.
И если проходить огонь и воду, только в таком формате и с таким результатом.
- Карта целевой аудитории
- Идеи по контенту
- Рекомендации по актуализации продуктовой линейки
- Рекомендации по улушению воронки продаж
Потрачено времени: месяц
Потрачено сил: очень много
Получено: новая методология, бесценный опыт, детально изученная база клиента.
Таким образом мы прошли путь от наивной, но надежной и эффективной команды до поседевшей, но такой же надежной и эффективной команды, улучшили нашу методологию и нашу услугу.
И если проходить огонь и воду, только в таком формате и с таким результатом.

А кстати, знаете в чем еще наша супер-сила?
Мы сами маркетологи и владельцы продукта, поэтому знаем, как применять результаты исследований, и можем дать еще серию встреч, чтобы законсалтить и помочь во внедрении результатов, вот так
